



Detection Antibody HRP labeling For diagnostics application (ELISA)
Diagnostic antibodies and antigens for Companion Animal disease testing
● Rabbit
Diagnostic antibodies and antigens for Swine disease testing
Diagnostic antibodies and antigens for Avian disease testing
Diagnostic antibodies and antigens for Multiple animal disease testing
Diagnostic antibodies and antigens for Ruminant disease testing
● Deer
Diagnostic antibodies and antigens for infectious and non-infectious Equine/Horse disease testing
SOCAIL MEDIA

1. Dissolve 5mg HRP in 1ml distilled water.
2. Add 200 μL of 0.1M NalO4 solution [1] (freshly prepared just before use) to the solution obtained in step 1 and stirred for 20 minutes at room temperature. Protect from light.
3. Put the solution obtained in step 2 into a dialysis bag and dialyzed with 1mM sodium acetate buffer [2] (PH4.4) at 4°C overnight.
4. Dissolve 10mg antibody in 1mL 0.01M carbonate buffer.
5. Add 20 μL 0.2M PH 9.5 carbonate buffer [3] to adjust the PH of the solution obtained in step 3 to 9.0~9.5, then immediately add to the antibody solution obtained in step 4, and gently stir at room temperature for 2 hours. Protect from light.
6. Add 100 μL 4mg/ml NaBH4 solution [4] (freshly prepared just before use), mix well, 4°C for 2 hours.
7. Filter the reaction mixture obtained in step 6 was by Sephadex-25 column, elute with PBS, and determine the optical density at 280 nm and 403 nm of each well.
8. Collect the solutions of the wells with light absorption both at 280 nm and 403 nm, which is HRP-labeled antibody conjugates, use directly or store at -20 °C.
[1] 0.1M NalO4 solution:
NaIO4 241 mg
Add distilled water to 10ml
[2] 1mM PH4.4 sodium acetate buffer:
0.2M NaAc 3.7ml
0.2M HAc 6.3ml
Add distilled water to 2000ml
[3] 0.2M PH 9.5 carbonate buffer:
Na2CO3 0.32g
NaHCO3 0.586g
Add distilled water to 50ml
[4] 4mg/ml NaBH4 solution:
NaBH4 4mg
Add distilled water to 1ml
Publications by Partners using Genemedi's COVID-19 products
Antigens for COVID-19 Rapid Test and Antibodies Screening
Grant et al[1]. described a half-strip Lateral flow assays (LFAs), which is a test format frequently utilized as the first step in assay development for a “full” LFA. Reverse transcription polymerase chain reaction (RT-PCR) based on oral swabs was used for confirmation of SARS-CoV-2 infection. However, high false negative rates, implementation costs and logistical problems with reagents during the global SARS-CoV-2 pandemic have hindered its universal on demand adoption. Lateral flow assays (LFAs) represent a class of diagnostic that, if sufficiently clinically sensitive, may fill many of the gaps in the current RT-PCR testing regime, especially in low- and middle-income countries.
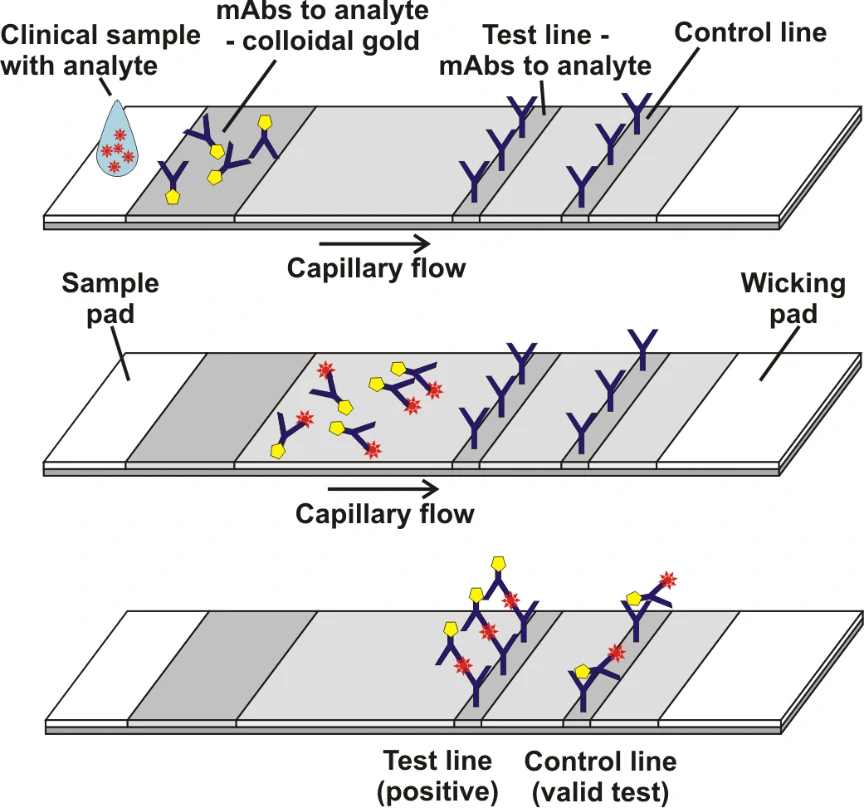
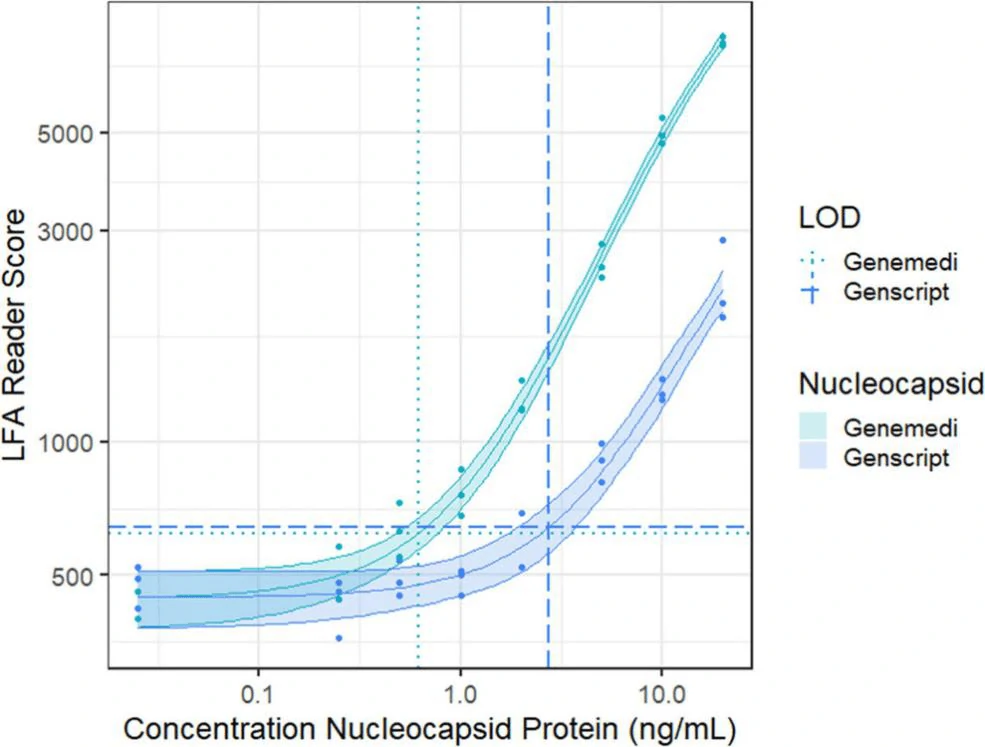
In this study, they presented a half-strip LFA for the detection of nucleocapsid protein of SARS-CoV-2. They used two commercially available SARS-CoV-2 nucleocapsid (N) proteins, from GeneMedi and Genscript to generate a dose response curve for the half-strip LFA. They found the limit of detection for the GeneMedi N protein was 0.65 ng/mL (95% CI of 0.53 to 0.77 ng/mL) and for the Genscript N protein was 3.03 ng/mL (95% CI of 0.00 to 7.44 ng/mL). The dose response curve, with 95% CI calculated in R using the drc package, is shown in Figure 2. The data indicated that the NP antigen from GeneMedi was a strong candidate for lateral flow assays (LFAs).
In another study, Cate et al [3]. described an extensive antibody screening effort that utilized high-throughput robotic antibody screening platform to screen through 673 combinations of antibody pairs that target the SARSCoV-2 nucleocapsid protein. These anti-nucleocapsid antibody pairs were tested as both capture and detection reagents with the goal of finding those pairs that have the greatest affinity for unique epitopes of the nucleocapsid protein of SARS-CoV-2 while also performing optimally in an LFA format.
Biolayer interferometry was performed on recombinant nucleocapsid proteins (NPs), for the purpose of selecting the most “native-like” analyte for LFA antibody screening. Initially, they used the estimated Rmax of five different NPs to quantify binding affinity against a random selection of 21 anti-nucleocapsid antibodies from different vendors. The metric Rmax was calculated based on theoretically saturating 100% of the bound antibody (ligand) with the analyte (NP). The NP antigen from GeneMedi was selected as the starting antigen for antibody screening because the average saturation value across 21 different anti-NP antibodies was closest to the theoretical Rmax of the antigen.
Antibody pair screening on LFAs in first-round consisted of a 11 × 11 grid of antibodies (121 unique pairs). For each pair, one antibody was striped on nitrocellulose as a test line (the “capture” antibody) and the other was coupled to latex nanoparticles using EDC/NHS chemistry (the “detector” antibody). The results of the first-round antibody pair screening on LFAs are given in Figure 5.
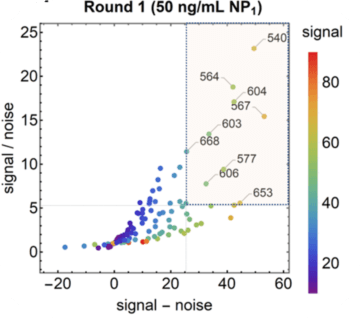
After the clinical based antibody pair screening, interestingly, they found the NP antigen from GeneMedi appeared to best predict antibody pair performance against clinical samples.
Antibody pairs for COVID-19 Serological Test and Immunoassay
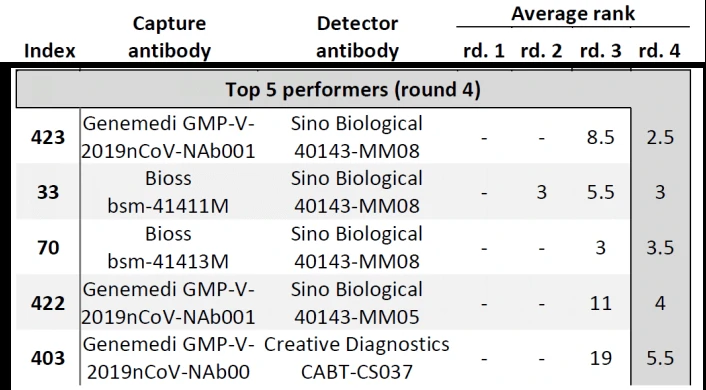
In Cate et al. ’s study[3], antibody screening results for anti-Nucleocapsid Antibodies towards the development of a SARS-CoV-2 Nucleocapsid Protein Antigen detecting Lateral Flow Assay, antibody pairs screening results in the top 5 in fourth-round from the clinical SARS-CoV-2 samples were shown in Figure 6. Among the top 5 antibody pairs, there were 3 antibody pairs from GeneMedi. This indicated that the NP antibodies from GeneMedi also behaved good performance in lateral flow assays (LFAs).
References
DOI: 10.1021/acs.analchem.0c01975[2] https://med.unr.edu/ddl/technology/lateral-flow-immunoassay[3] Cate, David; Hsieh, Helen; Glukhova, Veronika; Bishop, Joshua D; Hermansky, H Gleda; Barrios-Lopez, Brianda; et al. (2020): Antibody Screening Results for Anti-Nucleocapsid Antibodies Towards the Development of a SARS-CoV-2 Nucleocapsid Protein Antigen Detecting Lateral Flow Assay. ChemRxiv. Preprint. https://doi.org/10.26434/chemrxiv.12709538.v1
GeneMedi also provides pre-made the lentivirus, adenovirus and AAV vector for the gene ORF plasmids of 2019 nCoV (SARS2 coronavirus):
https://www.genemedi.com/i/2019-ncov-gene-vectors
SARS-CoV-2 neutralizing antibody validated post download
–Nab discovery and vaccines evaluation through SARS-CoV-2 wildtype/mutant variants pseudovirus based neutralizing assay(PBNA) and Spike-ACE2 competition binding assay
GeneMedi-SARS-CoV-2 WT and Spike Mutation Variants Pseudovirus (PSV) Based Cell Entry

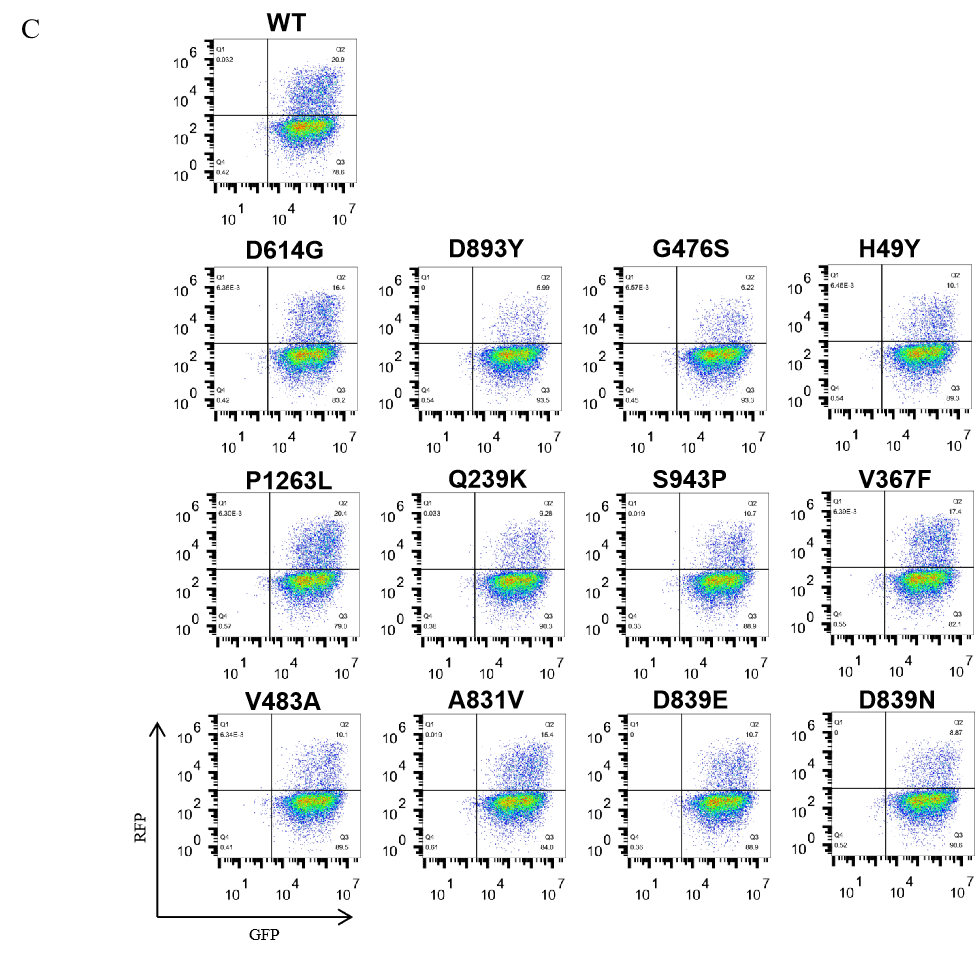
Figure. The Pseudovirus (PSV) Based Cell Entry assay was performed on 293T-hACE2 cells infected with GeneMedi-SARS-CoV-2 WT and Spike Mutation Variants (D614G, S943P, V367F, G476S, V483A, H49Y, Q239K, A831V, P1263L, D839Y/N/E:D839Y, D839N, D839E) Pseudovirus (PSV) Infection rate was determined by RFP+GFP+/GFP+ with FACS validation.
GeneMedi's anti-2019-nCoV Spike Neutralizing antibodies (Nabs) and Spike RBD protein binding validation
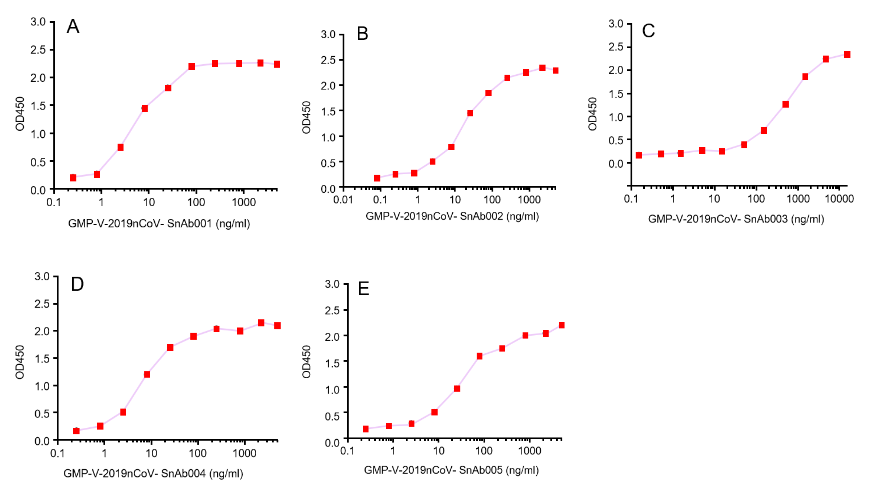
| Cat No. | Product | IC50 (ng/ml) |
| GMP-V-2019nCoV-SnAb001 | Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgG1) | 26.3 |
| GMP-V-2019nCoV-SnAb002 | Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgM) | 84.2 |
| GMP-V-2019nCoV-SnAb003 | Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgA) | 20.5 |
| GMP-V-2019nCoV-SnAb004 | Anti-2019-nCoV Spike (Spike RBD domain) mouse monoclonal neutralizing antibody (IgG1) | 81.9 |
| GMP-V-2019nCoV-SnAb005 | Anti-2019-nCoV Spike (Spike RBD domain) Cynomolgus monoclonal neutralizing antibody (IgG1) | 243 |
Figure. GeneMedi’s anti-2019-nCoV Spike Neutralizing antibodies (Nabs) block Recombinant 2019-nCoV(SARS-CoV-2) Spike RBD protein (GMP-V-2019nCoV-SRBD001) and hACE2 (GMP-H-ACE2002) binding.
A.GMP-V-2019nCoV-SnAb001:Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgG1)
B.GMP-V-2019nCoV-SnAb002:Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgM)
C.GMP-V-2019nCoV-SnAb003:Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgA)
D.GMP-V-2019nCoV-SnAb004:Anti-2019-nCoV Spike (Spike RBD domain) mouse monoclonal neutralizing antibody (IgG1)
E.GMP-V-2019nCoV-SnAb005:Anti-2019-nCoV Spike (Spike RBD domain) Cynomolgus monoclonal neutralizing antibody (IgG1)
GeneMedi's anti-2019-nCoV Spike Neutralizing antibodies (Nabs) competitive binding assay validation
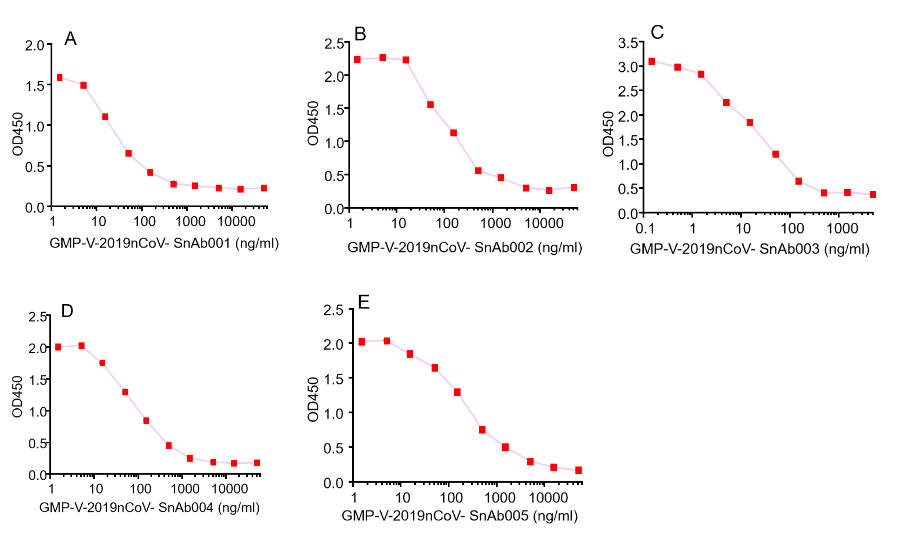
| Cat No. | Product | IC50 (ng/ml) |
| GMP-V-2019nCoV-SnAb001 | Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgG1) | 26.3 |
| GMP-V-2019nCoV-SnAb002 | Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgM) | 84.2 |
| GMP-V-2019nCoV-SnAb003 | Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgA) | 20.5 |
| GMP-V-2019nCoV-SnAb004 | Anti-2019-nCoV Spike (Spike RBD domain) mouse monoclonal neutralizing antibody (IgG1) | 81.9 |
| GMP-V-2019nCoV-SnAb005 | Anti-2019-nCoV Spike (Spike RBD domain) Cynomolgus monoclonal neutralizing antibody (IgG1) | 243 |
Figure. GeneMedi’s anti-2019-nCoV Spike Neutralizing antibodies (Nabs) block Recombinant 2019-nCoV(SARS-CoV-2) Spike RBD protein (GMP-V-2019nCoV-SRBD001) and hACE2 (GMP-H-ACE2002) binding.
A.GMP-V-2019nCoV-SnAb001:Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgG1)
B.GMP-V-2019nCoV-SnAb002:Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgM)
C.GMP-V-2019nCoV-SnAb003:Anti-2019-nCoV Spike (Spike RBD domain) human monoclonal neutralizing antibody (IgA)
D.GMP-V-2019nCoV-SnAb004:Anti-2019-nCoV Spike (Spike RBD domain) mouse monoclonal neutralizing antibody (IgG1)
E.GMP-V-2019nCoV-SnAb005:Anti-2019-nCoV Spike (Spike RBD domain) Cynomolgus monoclonal neutralizing antibody (IgG1)
GeneMedi-SARS-CoV-2 WT and Spike Mutation Variants Pseudovirus (PSV) Based Neutralizing Assay with GeneMedi's anti-2019-nCoV Spike Neutralizing antibodies (Nabs)

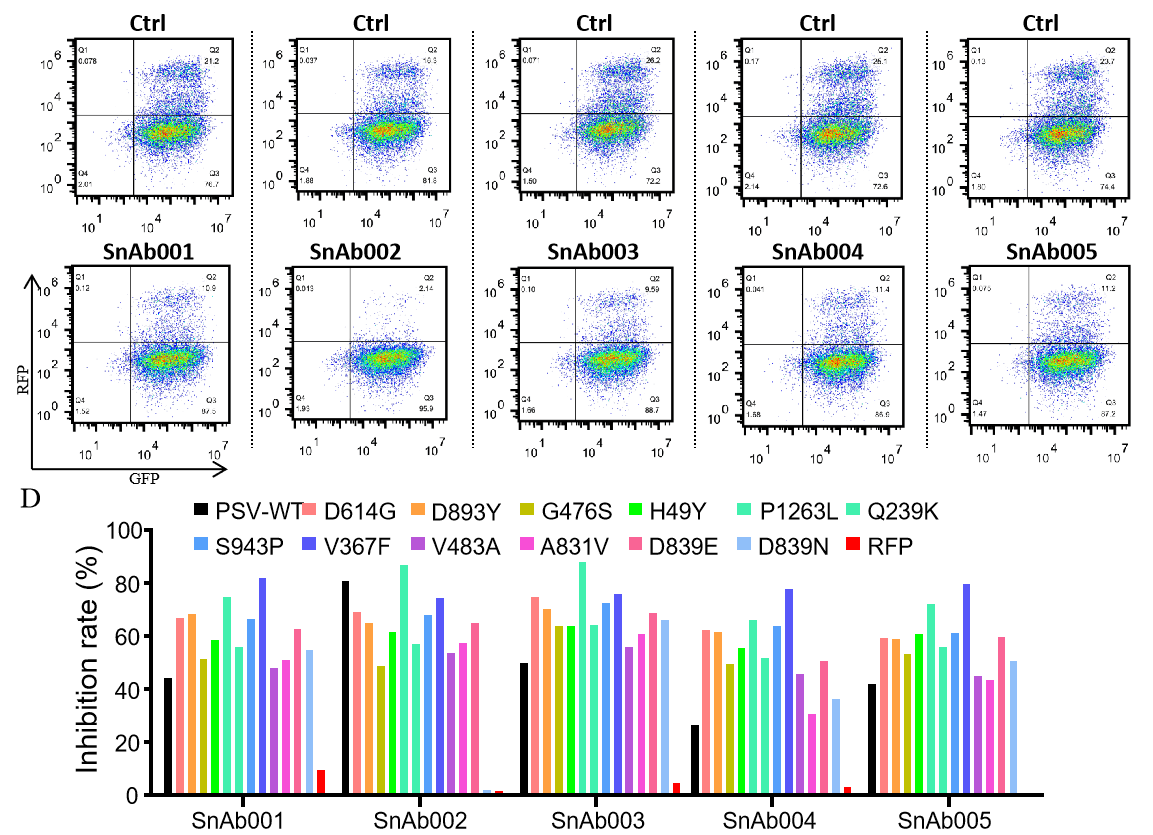
Figure. The Pseudovirus (PSV) Based Neutralizing Assay was performed on 293T-hACE2 cells infected with GeneMedi-SARS-CoV-2 WT and Spike Mutation Variants (D614G, S943P, V367F, G476S, V483A, H49Y, Q239K, A831V, P1263L, D839Y/N/E:D839Y, D839N, D839E) Pseudovirus (PSV) under treatment of GeneMedi’s anti-2019-nCoV Spike Neutralizing antibodies (Nabs) . Inhibition rate was determined by comparing the relative RFP+GFP+/GFP+ rate.
About SARS-CoV-2 (2019nCoV, novel Coronavirus) Spike protein, S1 Protein, Spike S1-NTD, Spike S1-CTD, Spike-RBD and Spike trimer protein.
1. SARS-CoV-2 (2019nCoV) Spike protein: SARS-CoV-2, a newly emerged pathogen spreading worldwide. The transmembrane spike (S) glycoprotein of SARS-CoV-2 that forms homotrimers protruding from the viral surface is known to mediate coronavirus entry into host cells. It has been reported that spike protein can bind with high affinity to human ACE2 and uses it as an entry receptor to invade target cells.
2. SARS-CoV-2 (2019nCoV) spike S1 protein: The spike protein is a large type I transmembrane glycoprotein comprises two functional subunits, S1 and S2. S1 subunit of spike protein is responsible for binding to the host cell receptor. S2 subunit is responsible for fusion of the viral and cellular membranes.
3. SARS-CoV-2 (2019nCoV) spike S1-NTD and S1-CTD: For most coronaviruses, the N-terminal domain (NTD) of the S1 subunit attaches to cellular carbohydrates and the C-terminal domain of S1 (S1-CTD) binds to a cellular protein receptor. Carbohydrate binding by the S1 N-terminal domain is thought to keep the virus in close proximity to the host cell surface, whereas engagement of specific protein receptors by the S1-CTD is thought to initiate a series of conformational changes in the spike that ultimately result in membrane fusion and delivery of the viral genome to the cytosol.
4. SARS-CoV-2 (2019nCoV) Spike RBD: S1 subunit of spike protein contains a receptor binding domain (RBD), which is responsible for recognizing the cell surface receptor.
5. SARS-CoV-2 (2019nCoV) Spike trimer protein: The transmembrane spike (S) glycoprotein of SARS-CoV-2 usually forms homotrimers protruding from the viral surface. S trimers are extensively decorated with N-linked glycans that are important for proper folding and for modulating accessibility to host proteases and neutralizing Abs. It has been found that S glycoprotein trimers in highly pathogenic human coronaviruses appear to exist in partially opened states, while they remain largely closed in human coronaviruses associated with common colds.
About SARS-CoV-2 (2019nCoV, novel Coronavirus) Envelop protein (Coronavirus E protein)
1. SARS-CoV-2 (2019nCoV) E protein: E protein is the smallest major structural proteins. It has a N-terminal ectodomain and a C-terminal endodomain with ion channel activity. During the replication cycle, E protein is abundantly expressed inside the infected cell, but only a small portion is incorporated into the virus envelope. The majority of the protein participates in viral assembly and budding. E protein is important in virus production and maturation. Recombinant CoVs without E have been shown to exhibit significantly reduced viral titres, crippled viral maturation, or yield incompetent progeny.
About SARS-CoV-2 (2019nCoV, novel Coronavirus) membrane protein (Coronavirus M protein)
1. SARS-CoV-2 (2019nCoV) M protein: Coronavirus M protein is believed to define the shape of the viral envelope,which contains three transmembrane domains. It has a small N-terminal glycosylated ectodomain and a much larger C-terminal endodomain that extends 6–8 nm into the viral particle. M protein usualy exists as a dimer, and may adopt two different conformations allowing it to promote membrane curvature as well as bind to the nucleocapsid.
About SARS-CoV-2 (2019nCoV, novel Coronavirus) Nucleocapsid protein (Coronavirus N protein)
1. SARS-CoV-2 (2019nCoV) N protein: Coronavirus N protein is required for coronavirus RNA synthesis, and has RNA chaperone activity that may be involved in template switch. Nucleocapsid protein is a most abundant protein of coronavirus. N protein packages the positive strand viral genome RNA into a helical ribonucleocapsid (RNP) and plays a fundamental role during virion assembly through its interactions with the viral genome and membrane protein M. Plays an important role in enhancing the efficiency of subgenomic viral RNA transcription as well as viral replication. Because of the conservation of N protein sequence and its strong immunogenicity, the N protein of coronavirus is chosen as a diagnostic tool.
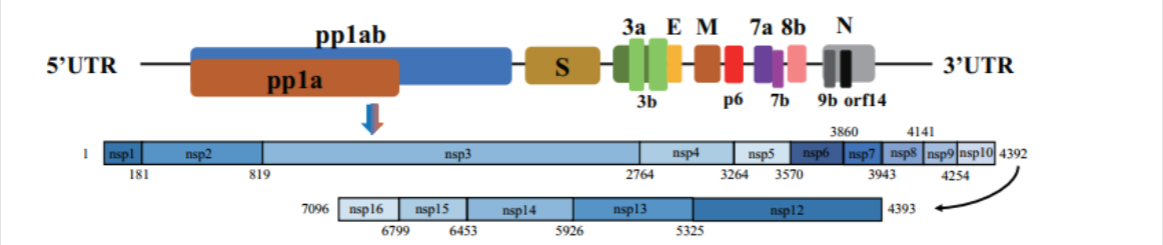
About SARS-CoV-2 (2019nCoV, novel Coronavirus)Non-structure protein (Nsp1-Nsp16)
2019nCoV contains 16 Non-structure protein (Nsp1-Nsp16) that may be drugable targets for antiviral compounds discovery against COVID-191.
| Non-structure proteins | Starting position (aa) | Ending position (aa) | Length (aa) |
| nsp1 | 1 | 180 | 180 |
| (leader protein) | |||
| nsp2 | 181 | 818 | 638 |
| nsp3 | 819 | 2763 | 1945 |
| (Papain-Like proteinase, PLpro) | |||
| nsp4 | 2764 | 3263 | 500 |
| nsp5 | 3264 | 3569 | 306 |
| (Mpro, Main proteinase, 3C-like proteinase) | |||
| nsp6 | 3570 | 3859 | 290 |
| nsp7 | 3860 | 3942 | 83 |
| nsp8 | 3943 | 4140 | 198 |
| nsp9 | 4141 | 4253 | 113 |
| nsp10 | 4254 | 4392 | 139 |
| (growth-factor-like protein) | |||
| nsp12 | 4393 | 5324 | 932 |
| (RdRP,NA-dependent RNA polymerase) | |||
| nsp13 | 5325 | 5925 | 601 |
| (RNA 5′-triphosphatase) | |||
| nsp14 | 5926 | 6452 | 527 |
| (3′-to-5′ exonuclease) | |||
| nsp15 | 6453 | 6798 | 346 |
| (endoRNAse) | |||
| nsp16 | 6799 | 7096 | 298 |
| (2’O-MTase, 2′-O-ribose methyltransferase) |
1. Nsp3: Nsp3 (200 kDa) is the largest protein encoded by the coronavirus (CoV) genome. Nsp3 is an essential component of the replication and transcription complex. It comprises various domains, the organization of which differs between CoV genera, due to duplication or absence of some domains. However, the N-terminal region of the Nsp3 is highly conserved among CoV, containing a ubiquitin-like (Ubl) globular fold followed by a flexible, extended acidic-domain (AC domain) rich in glutamic acid (38%). Next to the AC domain is a catalytically active ADP-ribose-1″-phosphatase (ADRP, app-1″-pase) domain (also called macro domain or X domain) thought to play a role during synthesis of viral subgenomic RNAs. SARS Unique Domain (SUD), a domain not yet identified in other coronaviruses from alphacoronavirus and betacoronavirus, follows next. The SUD domain binds oligonucleotides known to form G-quadruplexes. Downstream of the SUD domain is a second Ubl domain and the catalytically active PLpro domain that proteolytically processes the Nsp1/2, Nsp2/3 and Nsp3/4 cleavage sites. Downstream of PLpro are found a nucleic acid-binding domain (NAB) with a nucleic acid chaperon function, which is conserved in betacoronavirus and gammacoronavirus, and one uncharacterized domain termed the marker domain (G2M). Following the G2M are two predicted double-pass transmembrane domains (TM1–2 and TM3–4), a putative metal binding region (ZN) and the Y domain of unknown function (subdomains Y1–3).
2. Nsp5: Nsp5 protease (3CLpro; Mpro) mediates processing at 11 distinct cleavage sites, including its own autoproteolysis, and is essential for virus replication. Nsp5 exhibits a conserved three-domain structure and catalytic residues.
3. Nsp10: Nsp10 (18 kDa) is well conserved among coronaviruses and encoded by ORF1a. It’s thought to serve as an important multifunctional cofactor in replication. Nsp10 was shown to interact with itself, as well as with Nsp1, Nsp7, Nsp14, and Nsp16. The important role of Nsp10 is responsible for RNA synthesis. It was shown that a murine hepatitis virus (MHV) temperature-sensitive mutant carrying a non-synonymous mutation in the Nsp10 coding sequence had a defect in minus-strand RNA synthesis at non-permissive temperatures.
4. Nsp12: Nsp12 (102 kDa) is a multidomain RNA polymerase, which is the most conserved protein in coronaviruses. Nsp12 contains an RNA-dependent RNA polymerase (RdRp) domain in its C-terminal, which is essential for the viral replication and transcription.
5. Nsp16: Nsp16 is an SAM-dependent nucleoside-2’O-methyl-transferase (2’O-MTase). The mRNA cap for coronaviruses is completed by Nsp16, which ensures formation of a protective cap-1 structure that prevent recognition by either MDA5 or IFIT proteins. Finally, the NSP16/NSP10 complex finishes coronavirus capping process permitting viral infection with reduced host recognition.
About COVID-19 pandemic, Coronavirus (Coronavirus) and genome of SARS-CoV-2 (2019nCoV)
COVID-19 pandemic is caused by 2019nCoV (SARS-CoV-2, a novel coronavirus) infection.The 2019-nCoV genome was annotated to possess 14 ORFs encoding 27 proteins1.
| Gene name of 2019nCoV (SARS-CoV-2, a novel coronavirus) | Coding region(nt) | Protein length(aa) |
| orf1a | 266-13483 | 4405 |
| orf1ab | 266-13468, 13468-21555 | 7096 |
| S | 21563-25384 | 1273 |
| 3a | 25393-26220 | 275 |
| 3b | 25814-25882 | 22 |
| 26183-26281 | 32 | |
| E (envelope protei) | 26245-26472 | 75 |
| M (matrix protein) | 26523-27191 | 222 |
| p6 | 27202-27387 | 61 |
| 7a | 27394-27759 | 121 |
| 7b | 27756-27887 | 43 |
| 8b | 27894-28259 | 121 |
| 9b | 28284-28577 | 97 |
| N(nucleocapsid) | 28274-29533 | 419 |
| orf14 | 28734-28955 | 73 |
Collection of COVID-19 landscape knowledge base
Viral vector-based vaccine; DNA-based vaccine; RNA based vaccine – A landscape for vaccine technology against infectious disease, COVID-19 and tumor.
COVID-19 landscape Knowledge Base
An Insight of comparison between COVID-19 (2019-nCoV disease) and SARS in pathology and pathogenesis
Landscape Coronavirus Disease 2019 test (COVID-19 test) in vitro — A comparison of PCR vs Immunoassay vs Crispr-Based test
References
1. Wu, A. et al. Genome Composition and Divergence of the Novel Coronavirus (2019-nCoV) Originating in China. Cell Host Microbe, doi:10.1016/j.chom.2020.02.001 (2020).
